为什么需要ES数据持久化?
持久化涉及到哪几个方面?
持久化会丢失数据么?
带着这些疑问,我去百度一下,然后总结到这里。嘿嘿~
为什么es需要持久化
如果没有用 fsync 把数据从文件系统缓存刷(flush)到磁盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘
持久化流程是怎么样的?
先看一个请求过来es集群怎么处理的
- 当一个写请求进来,客户端随机找到一个节点,这个节点就是协调节点(coordinating node,集群中的每个节点都是协调节点)
2.协调节点查询集群状态信息并计算路由,将请求发送到真正处理请求的节点(primary shard所在的节点),计算方式shard = hash(routing) % num_of_primary_shards
3.包含主分片的节点处理写入请求,并将数据同步到包含副本分片的节点
4.coordinating node收到包含主分片的节点的响应信息,将最终结果返回给客户端
知识准备:
1 在es和磁盘之间的是文件系统缓存(FileSystemCache)。
2 refresh 是指把内存缓存区的数据刷新到段里
3 flush 是指执行段提交,并且清空事务日志;分片每30分钟被自动刷新(flush),或者在 translog 太大(512MB)的时候也会刷新
index.translog.flush_threshold_period 每隔多长时间执行一次flush(默认30m)
index.translog.flush_threshold_size 当事务日志大小到达此预设值,则执行flush。(默认512mb)
index.translog.flush_threshold_ops 当事务日志累积到多少条数据后flush一次。那么持久化流程发生在哪一步呢,当然是第3步了(画外音:感觉好nc),路由到对应的节点以及对应的主分片时,会做以下的事:
1 将数据写入到内存缓冲区(in-memory buffer),并且追加进translog(事务日志)
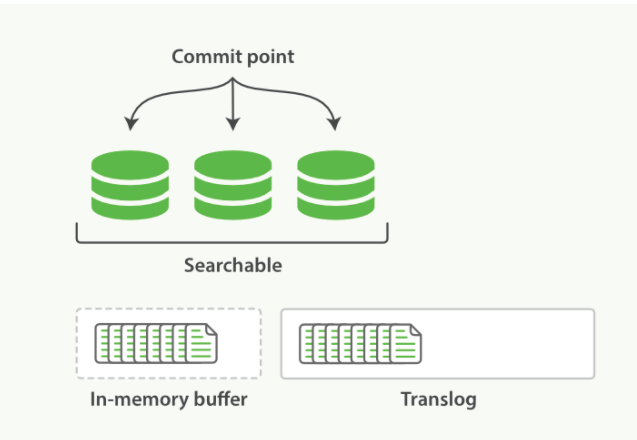
2 每隔1s数据从内存缓冲区refresh 到文件系统缓存,生成段文件(segment)(这时虽然还没有到磁盘,但是索引已经可以被搜索到了)。refresh之后内存缓冲区就清空了。但是translog不会。
![]()
3 随着translog文件越来越大时要考虑把内存中的数据刷新到磁盘中,这个过程称为flush(5s一次)
所有在内存缓冲区的文档都被写入一个新的段(segment)。
缓冲区被清空。
一个提交点被写入硬盘。
文件系统缓存通过 fsync 被刷新(flush)。
老的 translog 被删除。
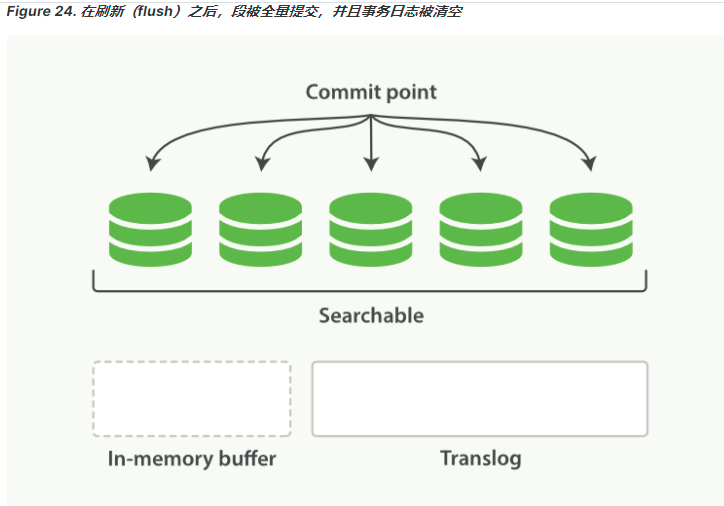
持久化会丢失数据么?
由上述原因可以知道,translog其实再宕机的时候会丢失5s左右的数据,具体看配置参数
小结:
es为了保证数据不丢失的问题,采用了translog和内存缓冲区(个人理解:进程缓冲区)双写
每1s刷新(refresh)内存缓冲区的数据,在文件缓冲区生成segment,这个段就存1s的数据。
每5s刷新translog数据,写入磁盘。当translog日志文件大到一定程度的时候,就会执行commit操作
commit 会把所有的缓存中的数据都写入磁盘,清空buffer,然后将一个commit point写入磁盘文件,里面标识者这个commit point 对应的所有segment file,同时强行将os cache中目前所有的数据都fsync到磁盘文件中去。最后清空现有 translog日志文件,重启一个translog,此时commit操作完成。
这个commit操作叫做flush,默认30分钟自动执行一次flush,但如果translog过大,也会触发flush。
translog会存放所有没被刷到磁盘的数据,es启动的时候从磁盘中最后一个commit point恢复已知的段,并且会把translog中所有在最后一次提交后发生的变更操作重放。translog 也被用来提供实时 CRUD。
1 segment 每1s生成一个什么时候进行段合并,
tiered(默认)
它能合并大小相似的索引段,并考虑每层允许的索引段的最大个数
log_byte_size
该策略不断地以字节数的对数为计算单位,选择多个索引来合并创建新索引
log_doc
与log_byte_size类似,不同的是前者基于索引的字节数计算,后者基于索引段文档数计算
配置:index.merge.policy.type: tiered
2 translog中的数据会不会跟segment重复
个人理解下来,translog 每5s落一次盘,在最后commit的时候并没有再次把translog的数据落盘,而只是把段合并后的数据写入到磁盘。且把旧的translog文件删除了,所以磁盘里只有一份数据。也就是说不会重复。
网上的答案:
segment 和 translog 最终肯定都是写文件,但是两者是各自写各自的,不相干, segment 是索引类的文件,在写之前要经过大量的计算,比如分词、构建倒排索引等,它存的是索引相关的数据,而 translog 只是简单的追加数据增删改的操作记录,只是为了后面服务意外中止时通过回放这个记录来减少数据的丢失。讲到这里你第一个问题就解决了,segment 记录的数据与 translog 是不一样的。
那么涉及到写文件逻辑就一样了,都要 fsync 后才能保证真正落盘不丢数据,fsync 前数据是存在 OS 文件系统 Cache 里面的,如果服务意外中止,那么这部分数据就丢失了,即便重启也不会再 fsync。因此 translog 其实也是会丢数据的,所以才有translog 的相关参数(index.translog.sync_interval)来控制它 fsync 的频率,这个频率越高,丢的数据就越少。降到这里你第二个问题就解决了。translog 一样会丢数据,你要设置好相关参数,确保自己可用接受相应的数据丢失
es数据读取流程
查询我们最简单的方式可以分为两种:
根据ID查询doc
根据query(搜索词)去查询匹配的doc
public TopDocs search(Query query, int n);
public Document doc(int docID);
根据ID去查询具体的doc的流程是:
检索内存的Translog文件
检索硬盘的Translog文件
检索硬盘的Segement文件
根据query去匹配doc的流程是:
同时去查询内存和硬盘的Segement文件
从上面所讲的写入流程,我们就可以知道:Get(通过ID去查Doc是实时的),Query(通过query去匹配Doc是近实时的)
因为segement文件是每隔一秒才生成一次的
Elasticsearch查询又分可以为三个阶段:
QUERY_AND_FETCH(查询完就返回整个Doc内容)
QUERY_THEN_FETCH(先查询出对应的Doc id ,然后再根据Doc id 匹配去对应的文档)
DFS_QUERY_THEN_FETCH(先算分,再查询)
「这里的分指的是 词频率和文档的频率(Term Frequency、Document Frequency)众所周知,出现频率越高,相关性就更强」
一般我们用得最多的就是QUERY_THEN_FETCH,第一种查询完就返回整个Doc内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求。
QUERY_THEN_FETCH总体的流程流程大概是:
客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
每个分片将自己搜索出的结果(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
Query Phase阶段时节点做的事:
协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
数据节点(在每个分片内做过滤、排序等等操作),返回doc id给协调节点
Fetch Phase阶段时节点做的是:
协调节点得到数据节点返回的doc id,对这些doc id做聚合,然后将目标数据分片发送抓取命令(希望拿到整个Doc记录)
数据节点按协调节点发送的doc id,拉取实际需要的数据返回给协调节点
主流程我相信大家也不会太难理解,说白了就是:由于Elasticsearch是分布式的,所以需要从各个节点都拉取对应的数据,然后最终统一合成给客户端
只是Elasticsearch把这些活都干了,我们在使用的时候无感知而已。
参考链接:
https://www.cnblogs.com/Java3y/p/12220627.html
https://www.pianshen.com/article/64781584740/
https://www.pianshen.com/article/64781584740/#ES_70
https://www.cnblogs.com/ssqq5200936/p/11350444.html