了解一个工具的基本路线呢,它是什么,它能干什么,它是怎么做到的。
1 elasticsearch 是什么?
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎. 以下简称es
2 elasticsearch 能做什么
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
海量数据量级下的近实时(秒级)性能支持,
以及无比强大的搜索和聚合分析的语法支持
(hhhh 是不是听起来很D)
3 elastics的基本概念
关系型数据库 ElasticSearch
库(database) 索引(index)
表(table) 类型(Type)
行(row) 文档(document)
列(column) 字段(field)
Schema(约束) Mapping(映射)
SQL(结构化查询语言) DSL索引
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合
索引由其名称(必须全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。
类型(7.x版本取消了这个概念)
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。
文档
文档是索引和搜索的原子单位,它是包含了一个或多字段(field)的容器,采用JSON格式表示。文档由一个或多个字段组成,每个字段拥有一个名字及一个或多个值,对于es来说一条数据就是一个文档:
{
"name":"Jack",
"sex":"Male",
"age":18,
"birthDate": "2003/05/01",
"about": "I love dudu",
"interests" : ["sports","game"]
}文档元数据:
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index 索引名
一个 索引 应该是因共同的特性被分组到一起的文档集合。
名字必须小写,不能以下划线开头,不能包含逗号
_type 文档表示的对象类别,文档名
一个 _type 命名可以是大写或者小写
不能以下划线或者句号开头,不应该包含逗号。
长度限制为256个字符
_id 文档唯一标识
ID 是一个字符串,当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id ,要么让 Elasticsearch 帮你生成;es允许自己设置id,也可以由es根据URL-safe,基于Base64编码且长度为20个字符的GUID字符串。这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零。
字段:
字段的名字可以是任何合法的字符串,但不可以 包含英文句号(.)。
字段可以是一个简单的值(如字符串、数字、日期), 也可以是一个数组, 还可以嵌套一个对象或多个对象.
字段类似于关系数据库中表数据的列, 每个字段都对应一个类型.
可以指定如何分析某一字段的值, 即对field指定分词器.
正排索引
正排索引也称为"前向索引",它是创建倒排索引的基础。
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。
他适合根据文档ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
优点:工作原理非常的简单。
缺点:检索效率太低,只能在简单的场景下使用。
倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表
倒排索引主要由3部分组成:
单词词典(Term Dictionary)
倒排列表(Posting List)
倒排文件(Inverted File)
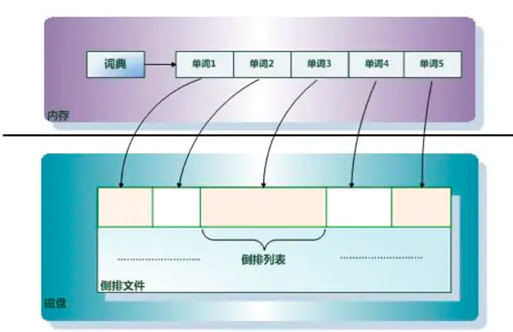
三者关系大概如上单词词典(Term Dictionary):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率(作关联性算分),每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件
倒排列表特性
记录出现过某个单词的文档列表
同时还记录单词在所有文档中的出现次数和偏移位置
倒排列表元素数据结构:((DocID;TF;
其中:
DocID:出现某单词的文档ID
TF(Term Frequency):单词在该文档中出现的次数(词频)
POS:单词在文档中的位置
举例
有下面单个文档
内容
文档1 百度的年度目标
文档2 AI技术生态部的年度目标
文档3 AI市场的年度目标则他们生成的倒排索引
单词ID 单词 逆向文档频率 倒排列表(DocID;TF;)
1 目标 3 (1;1;<3>),(2;1;<5>),(3;1;<4>)
2 年度 3 (1;1;<2>),(2;1;<4>),(3;1;<3>)
3 AI 2 (2;1;<1>),(3;1;<1>)
4 技术 1 (2;1;<2>)
5 生态 1 (2;1;<3>)
6 市场 1 (3;1;<2>) 比如单词“年度”,单词ID为2,在三个文档中出现过,所以逆向文档频率为3,同时倒排索引中的元素也有三个:(1;1;<2>),(2;1;<4>),(3;1;<3>)。拿第一个元素(1;1;<2>)进行说明,他表示“年度”在文档ID为1的文档中出现过1次,出现的位置是第二个单词
倒排索引的搜索过程

集群节点
- 主节点
master节点:节点,负责索引元数据的处理以及索引的增删改操作,以及索引分片分配。 - 数据节点
data节点:数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
节点只存储数据,不参与主节点选举 - 客户端节点
client节点:当主节点和数据节点配置都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,充当请求的负载平衡器。
主要针对海量请求时进行负载均衡 - 协调节点
Coordinating
协调节点,是一种角色,而不是真实的Elasticsearch的节点,你没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点,都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询子句分发到其它的节点,然后合并各个节点返回的查询结果,最后返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。毫无疑问,协调节点会对CPU、Memory要求比较高
参考链接:https://juejin.cn/post/6844904051994263559
https://blog.csdn.net/zwgdft/article/details/54585644