-
倒排索引
百度百科解释:
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。 -
王德法:没什么原因,就想写个王德法
概念
- 倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案, 是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表
结构
- 单词词典:term dictionary
- 倒排文件: inverted files
- Posting List(记录表)
- 文档id(DocId,Document Id),包含单词的所有文档唯一id,用于去正排索引中查询原始数据
- 词频(TF,Term Frequency),记录 Term 在每篇文档中出现的次数,用于后续相关性算分。
- 位置(Position),记录 Term 在每篇文档中的分词位置(多个),用于做词语搜索(Phrase Query)。
- 偏移(Offset),记录 Term 在每篇文档的开始和结束位置,用于高亮显示等。
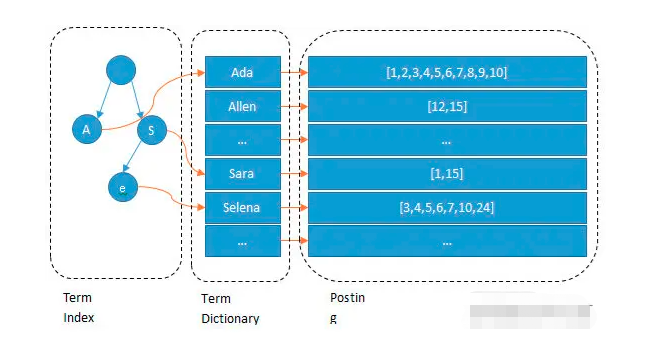
- Posting List(记录表)
一脸懵吧:
描述一下这几者之间的关系:
- es分别给每个field建立一个倒排索引,Ada,Allen、Sara、Selena 都叫term,而Posting list 就是一个int的数组,这个数组存储了文档的id(DocId)。
- es为了能快速找个某个term,把所有term来个排序,采用二分法查找term。O(LogN)的复杂度查找;就像通过字典查找一样,这就是Term Dictionary
- es通过内存查找term,但是term太多,term dictionary就太大,内存放不下,于是又出现了term index就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树。
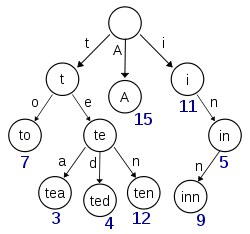
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
所以term index不需要存下所有的term,而仅存储部分词的前缀与Term Dictionary的block之间的映射关系,再结合FST压缩技术,可以使term index 缓存到内存中。以使term index缓存到内存中。从term index查到对应的term dictionary的offset位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
es通过term index 找到对应term dictionary的block位置,然后去磁盘上捞取term。所以最终term是存在磁盘上的而不是内存中,term index 是存在内存中的。
FST
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。这玩意超纲了,回头再研究。
在内存中是以FST(Finite State Transducers)的形式保存的,其特点是非常节省内存。FST有两个优点:
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2)查询速度快。O(len(str))的查询时间复杂度
Posting list
为了能够高效的计算交集和并集,我们需要posting list是事先排序好的,这样我们就可以使用delta-encoding (增量编码);这个数据是存储在磁盘的。
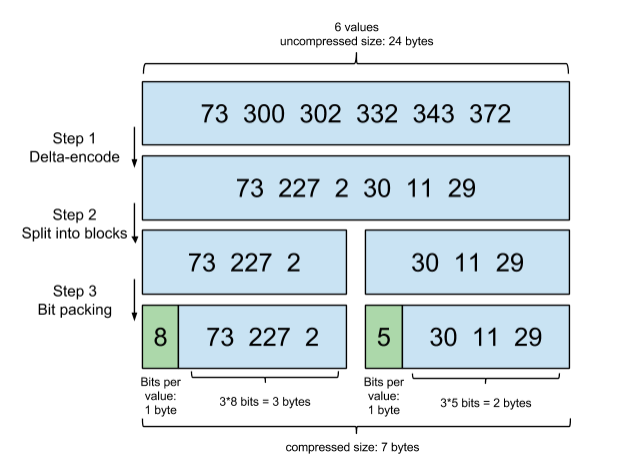
官方图释
稍加解释:
- 文档id列表为[73, 300, 302, 332,343, 372]id列表首先要从小到大排好序;
- 增量编码(delta-encoding):就是从第2个数开始每个数存储与前一个id的差值,即300-73=227,302-300=2,一直到最后[73,227,2,30,11,29],需要注意的是列表的差值都是0到255之间,这样每个值就仅需1个字节byte
- 分区块(split into blocks): 将这些差值放到不同的区块,Posting list被分为256个区块(blocks),图中示例为了方便展示使用了2个区块,即每区块3个数[73,227,2] [30,11,29]
- 位组合(Bit packing):计算每组3个数中最大的那个数需要占用bit位数,比如30、11、29中最大数30最小需要5个bit位存储 (2^5=32),然后把这个信息放到块的头部
- 这样11、29也用5个bit位存储,这样才占用15个bits,不到2个字节(8bit=1byte字节),同理227需要8bit(2^8=256),那么73和2同样用8bit,3*8=24个bits一共 3bytes,再加上头部的每块1byte共计1 + 3 + 1 + 2 = 7(bytes)
这个压缩技术在文献中被称之为Frame Of Reference(FOR)【中文直译:参照系】。lucene4.1版本开始使用。
优点:编码技术对里边的数据进行压缩,节约磁盘空间。
Roaring bitmaps
PostingList里边存的是文档ID,我们查的时候往往需要对这些文档ID做交集和并集的操作(比如在多条件查询时),PostingList使用Roaring Bitmaps来对文档ID进行交并集操作
官方图示
- 因为我们只缓存经常使用的过滤器,所以压缩比并不像倒排索引那样重要,倒排索引需要为匹配的文档编码every possible term;
- 然而,我们需要缓存过滤器比重新执行过滤器更快,因此使用良好的数据结构很重要;
- 缓存过滤器存储在内存中,而发布列表通常存储在磁盘上
出于这些原因,对于反向索引和缓存过滤器,最好的编码技术不一定是相同的。
那么我们应该用什么呢?显然,最重要的要求是有一些快速的:如果您的缓存过滤器比再次执行过滤器慢,它不仅消耗内存,而且使您的查询更慢。编码越复杂,就越有可能因为CPU使用量的增加而降低编码和解码的速度,所以让我们看看编码有序的整数列表的简单选项:
整型数组 integer array
最简单的方法可能是:将doc id存储在一个数组中。这使得迭代非常简单,但是压缩真的很糟糕。这种编码技术需要每个条目4个bytes(字节,因为int在机器上是4byte=32bit),这使得 密集过滤器 (dense filter)非常消耗内存。如果您有一个包含100M文档的段(segment),以及一个匹配大多数文档的过滤器,那么在这个段上缓存一个过滤器大约需要400MB内存。理想情况下,我们应该在 密集数据集 上使用更高效的内存
位图 bitmap
整数密集数据集是位图的一个很好的用例。位图是一个数组,其中每个条目只有一个位(bit),所以它们只有两个可能的值:0或1。为了知道docID是否包含在位图中,需要读取索引docID处的值。
0表示集合不包含这个docID,而1表示集合包含这个docID。
如果迭代需要统计连续的0,这实际上是非常快的,因为cpu有专门的指令。
如果我们比较选项1,在密集过滤器上内存使用要好得多,因为我们现在只需要100Mbits = 12.5MB(100/8=12.5);
但稀疏(sparse)数据集有一个弊端:虽然整型数组每个条目4字节,但我们现在不论多少个条目都需要12.5MB的内存。就浪费了很多的存储空间 ,emmm 这就坑爹了。
很长一段时间以来,Lucene一直在使用这种位图来将过滤器缓存到内存中。但是在Lucene 5中,我们切换到了Daniel Lemire的咆哮位图。更多背景信息,请参见LUCENE-5983
咆哮位图 Roaring bitmaps
来看看今天party 真正的owner。咆哮位图的目标是在我们刚刚描述的两个选择中取其所长。
- 首先根据16个最高位将帖子列表分割成块。这意味着,例如,第一个块将编码0到65535之间的值,第二个块将编码65536到131071之间的值,等等。
- 然后在每个块中单独编码16个最低位:如果它的值小于4096,将使用数组(integer array),否则使用位图(bitmap)。在这个阶段需要注意的重要一点是,虽然我们以前使用上述数组编码,每个值需要4个字节,但这里数组只需要存储每个值2个字节,因为块ID隐式地给了我们16个最高位
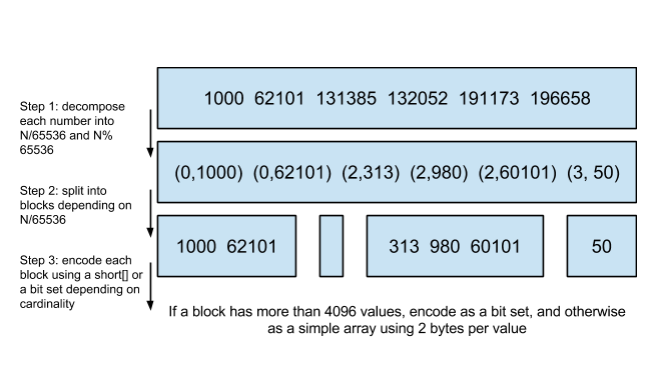
稍加解释:decompose 美 /ˌdiːkəmˈpoʊz/ 分解
- 分解每个数字分别对65536进行求商和余数,N/65536,N%65536,例如 131385/65536 商是2,余数是313,所以组成了(0,1000),(2,313)……等等。
- 按照上步求的商,分到不同的block里面,没有商是1的所以有个空
- 根据元素个数超过4096个,采用bitmap位图,不超过的用short类型的数组,每个数组元素2bytes
为什么使用4096作为一个阈值呢?因为在一个Block中超过这个数量的文档,位图比数组的内存效率更高!
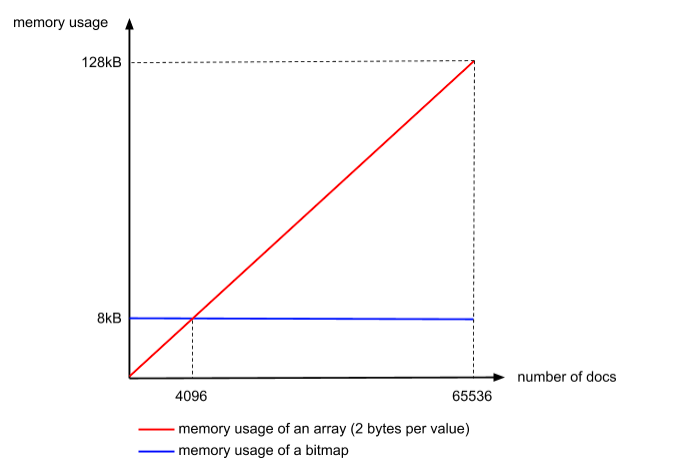
内存使用率红色的是数组,蓝色是位图,可见4096以内的数组使用率高啊。
这就是“咆哮位图”有趣的地方:它们基于两种快速编码技术,它们有非常不同的压缩特性,并根据内存效率动态地决定使用哪一种;
lucene咆哮位图特征:
- 遍历所有匹配的文档。如果在缓存过滤器上运行constant_score查询,则通常会使用此方法。
- 推进到集合中包含的大于或等于给定整数的第一个文档ID。如果您将过滤器与查询交叉,则通常会使用此方法。
没有一个指定的算法一直是优于其他的,甚至一些算法在某些特定环境下表现得很差劲
- 位图在稀疏集上表现很差,无论是在性能上还是在内存使用上
- 简单的int[]数组速度很快,但在密集的集合上内存占用非常高
总结:
- 倒排索引是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。所以它跟关系型数据库的索引不是一回事,类似于聚簇索引它是一种方法。
- es分词为term,term的集合叫term Dictionary(存放磁盘),term Dictionary会排序,因为要二分法查找,term Dictionary太大,内存装不下,所有抽象一层词缀叫term Index(存放内存),term Index 以FST数据结构来保存词的前缀,节省内存且查找速度快。
- Posting list : 存放词对应文档的ID,使用FOR,压缩数据,节省空间,使用Roaring Bitmaps 求出文档交集和并集
优秀的人为什么牛b,因为他们善于总结啊。
参考链接:https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps
https://juejin.cn/post/6844904051994263559#heading-3