-
创建表
CREATE TABLE jack
(
hansomeString,
ageUInt32,
sexUInt32
)
ENGINE = Memory -
插入表
insert into table jack(*) values('yes',18,1),('no',30,2);
如果想排除某个字段- insert into table jack(* except(age)) values('yes',1),('no',2);这样age字段就不会被插入了
-
清空表
truncate table if exists jack;
如果需要指定集群和数据库
truncate table if exists default.jack on cluster zk-server- 删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]
drop table if exists default.jack on cluster zk-server
- 删除表
-
查看表结构
- describe jack;
- show create table;
┌─statement─────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE jack.jack
(
hansomeString,
ageUInt32,
sexUInt32
)
ENGINE = Memory │
└───────────────────────────────────────────────────────────────────────────────────────────────┘
-
查询
- ALL子句
select sum(number) from numbers(10);
跟select sum(ALL number) from numbers(10) 一样 -
ARRAY JOIN
-
对于包含数组列的表来说是一种常见的操作,用于生成一个新表,该表具有包含该初始列中的每个单独数组元素的列,而其他列的值将被重复显示
听起来感觉比较抽象实操一下创建一个表 CREATE TABLE arrays_test ( s String, arr Array(UInt8) ) ENGINE = Memory; 插入数据 INSERT INTO arrays_test VALUES ('Hello', [1,2]), ('World', [3,4,5]), ('Goodbye', []); 先正常查一下 SELECT * FROM arrays_test ┌─s───────┬─arr─────┐ │ Hello │ [1,2] │ │ World │ [3,4,5] │ │ Goodbye │ [] │ └─────────┴───────┘ 然后使用 array join SELECT s, arr FROM arrays_test ARRAY JOIN arr; ┌─s─────┬─arr─┐ │ Hello │ 1 │ │ Hello │ 2 │ │ World │ 3 │ │ World │ 4 │ │ World │ 5 │ └──────┴─────┘ 再用left ARRAY JOIN SELECT s, arr FROM arrays_test LEFT ARRAY JOIN arr ┌─s───────┬─arr─┐ │ Hello │ 1 │ │ Hello │ 2 │ │ World │ 3 │ │ World │ 4 │ │ World │ 5 │ │ Goodbye │ 0 │ └───────┴─────┘ 使用别名 SELECT s, arr, a FROM arrays_test ARRAY JOIN arr AS a ┌─s─────┬─arr─────┬─a─┐ │ Hello │ [1,2] │ 1 │ │ Hello │ [1,2] │ 2 │ │ World │ [3,4,5] │ 3 │ │ World │ [3,4,5] │ 4 │ │ World │ [3,4,5] │ 5 │ └───────┴──────┴───┘
-
- Limit
- select * from arrays_test limit 1;
- select * from arrays_test limit 1,2;
- select * from arrays_test limit 2 offset 1;
- limit with ties 注意一定要搭配order by 使用
-
SELECT * FROM ( SELECT number%50 AS n FROM numbers(100) ) ORDER BY n LIMIT 0,5 WITH TIES 返回结果,虽然指定了LIMIT 5, 但第6行的n字段值为2,与第5行相同,因此也作为满足条件的记录返回。 简而言之,该修饰符可理解为是否增加“并列行”的数据。 ┌─n─┐ │ 0 │ │ 0 │ │ 1 │ │ 1 │ │ 2 │ │ 2 │ └───┘
-
- offset fetch clause
- offset和fetch可以让我们按比例来检索数据
- 格式 select from test_fetch order by a offset 1 row fetch first 3 rows only,它其实和SELECT FROM test_fetch ORDER BY a LIMIT 3 OFFSET 1; 是等价的,也可以搭配with ties使用
- ALL子句
-
分组
- select x from t_null_pig group by x 这里跟mysql的SQL_MODE=only_full_group_by要求差不多,group x 查询的只能有x
- 可以跟聚合函数,
-
聚合
-
排序
-
ALTER
- column 字段修改
- 添加新的字段 add column
- alter table mt add column if not exists id UInt32 default 0 FIRST;
给mt表增加一个 id 字段 UInt32 类型 默认为0 且插入到第一位。
- alter table mt add column if not exists id UInt32 default 0 FIRST;
- 删除字段 drop column
- alter table mt drop column number; 删除字段
- 字段改名
- alter table mt rename column id to idd;
- 字段注释
- alter table mt comment column if exisits idd 'id主键'
- 修改字段
- alter table mt modify column if exists idd UInt16 default 1;
- 修改字段顺序
- alter table users modify column c2 String FIRST 就把C2放到C1的前面(CREATE TABLE users (
c1 Int16,
c2 String
) ENGINE = MergeTree
ORDER BY c1;)
- alter table users modify column c2 String FIRST 就把C2放到C1的前面(CREATE TABLE users (
-
索引
-
在MergeTree中PRIMARY KEY 主键并不用于去重,而是用于索引,加快查询速度,MergeTree会根据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARY KEY 排序,相对于使用PRIMARY KEY 更常见的方式是通过ORDER BY 方式指定主键。
-
稀疏索引
-
稠密索引
在稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中每一行索引标记对应的是一段数据,而不是一行。稀疏索引的优势显而易见,仅需要使用少量的索引标记就能够记录大量的数据区间位置信息,而且数据量越大优势越明显。在MergeTree系列引擎表中对应的primary.idx文件就是稀疏索引,由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存 -
索引粒度
- 在ClickHouse MergeTree引擎中默认的索引粒度是8192,参数为index_granularity,一般我们不会修改此值,按照默认8192即可。我们可以通过以下sql语句查看每个MergeTree引擎表对应的index_granulariry的值:
show create table mt;显示 SETTINGS index_granularity = 8192 索引粒度对于MergeTree表引擎非常重要,可以根据整个数据的长度,按照索引粒度对数据进行标注,然后抽取对应的数据形成索引;
- 在ClickHouse MergeTree引擎中默认的索引粒度是8192,参数为index_granularity,一般我们不会修改此值,按照默认8192即可。我们可以通过以下sql语句查看每个MergeTree引擎表对应的index_granulariry的值:
-
索引形成过程
表数据以index_granularity的粒度(默认8192)被标记成多个小区间,其中每个区间最多8192行数据,每个区间标记后形成一个MarkRange,通过start和end表示MarkRange的具体范围;
数据文件也会按照index_granularity的间隔粒度生成压缩数据块;
由于是稀疏索引,MergeTree需要间隔index_granularity行数据生成一条索引,同时对应一个索引编号,每个MarkRange与一个索引编号对应,通过与start及end对应的索引编号的取值,可以得到对应的数值区间;索引编号对应的索引值会依据声明的主键字段获取,最终索引编号和索引值被写入primary.idx文件中保存。
假设一份数据共有192行,indexgranularity=3 那么一共有192/3=64个MarkRange区间,还有一个最大的区间为[0,+inf)
[0,3)[3,6)[6,9)...
ps:[a,b] 闭区间,包含两端,(a,b)开区间,不含两端的数字

其中strat:0,end:1 表示第一个markRange的开头和结尾的值的具体范围使用索引查询其实就是两个数值区间的交集判断,其中一个区间是有基于主键的查询条件转换而来的条件区间,而另一个区间是上图中MarkRange对应的数值区间。
-
整个索引查询的过程大致分为3个步骤:
1、生成查询条件区间
查询时首先将查询条件转换为条件区间,即便是单个值的查询条件也会转换成区间的形式,例如:
WHERE ID='A003'
['A003','A003'] //闭区间 包含边界![索引]
WHERE ID>'A000'
['A000',+inf]
WHERE ID<'A188'
(-inf,'A188']
WHERE ID like 'A006%'
('A006','A007']
- 递归交集判断
以递归的方式依次对MarkRange的数值区间与条件区间做交集判断,从最大的区间[A000,+inf)开:
如果不存在交集,则直接忽略掉整段MarkRange
如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断。
如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
- 合并MarkRange区间
将最终匹配的MarkRange聚在一起,合并他们的范围。
当查询条件WHERE ID ='A003'的时候,最终读取[A000,A003)和[A003,A006]两个区间的数据即可,他们对应的MarkRange(start:0,end:2)范围,而无其他无用的区间都被裁剪过滤掉,因为MarkRange转换的数值区间是闭区间,所以会额外匹配到临近的一个区间
- 二级索引(跳数索引)
除了一级索引之外,MergeTree同样支持二级索引,二级索引又称为跳数索引,由数据的聚合信息构建而成,根据索引类型的不同,其聚合信息的内容也不同,跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
跳数索引需要在Create语句内定义,完整语法如下:
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity
对以上参数的解释如下:
index_name:定义的二级索引名称
index_type:跳数索引类型,最常用就是minmax索引类型。minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录,能够快速跳过无用的数据区间。
granularity:定义聚合信息汇总的粒度。
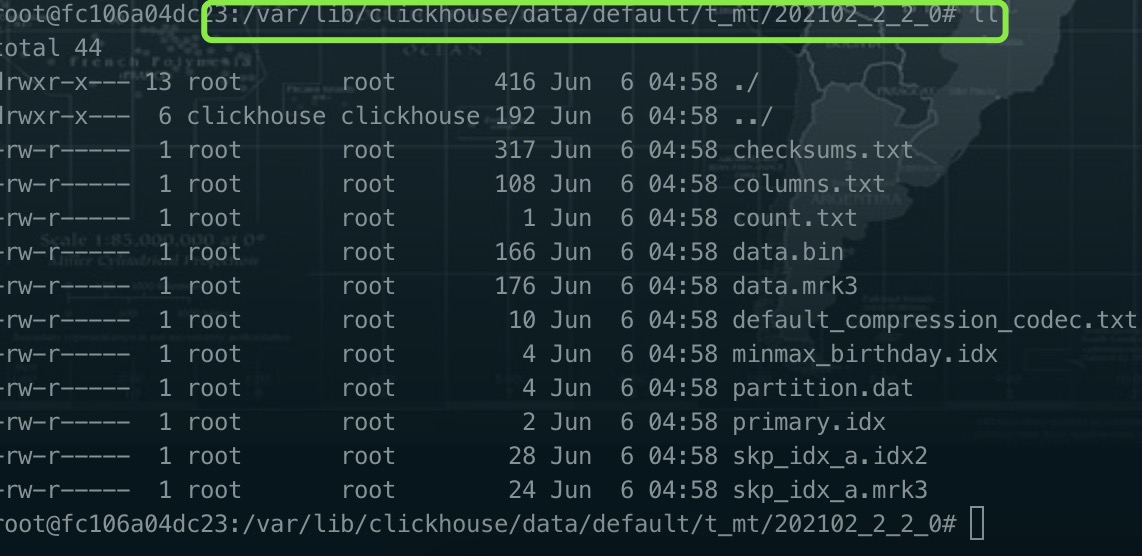
与一级索引一样,如果在建表语句中声明了跳数索引,则会在路径“/var/lib/ClickHouse/data/DATABASE/TABLE/PARTITION/”目录下生成索引与标记文件(skp_idx.idx与skp_idx.mrk)。
在接触跳数索引时,很容易将index_granularity与granularity概念混淆,对于跳数索引而言,index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度,也就是说,granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
minmax跳数索引的生成规则
minmax跳数索引聚合信息是在一个index_granularity区间内数据的最小和最大极值。首先,数据按照index_granularity粒度间隔将数据划分成n段,总共有[0~n-1]个区间(n=total_rows/index_granularity,向上取整),接着根据跳数索引从0区间开始,依次按index_granularity粒度从数据中获取聚合信息,每次向前移动1步,聚合信息逐步累加,最后当移动granularity次区间时,则汇总并生成一行跳数索引数据。
以下图为例:假设index_granularity=8192且granularity=3,则数据会按照indexgranularity划分成n等份,MergeTree从第0段分区开始,依次获取聚合信息,当获取到第3个分区时(granularity=3),则汇总并生成第一行minmax索引(前3段minmax极值汇总后取值为[1,9])
- minmax跳数索引案例:
删除表 t_mt
node1 🙂 drop table t_mt;
重新创建t_mt表,包含二级索引
node1 :)CREATE TABLE t_mt
(
id UInt8,
name String,
age UInt8,
birthday Date,
location String,
INDEX a id TYPE minmax GRANULARITY 5
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(birthday)
ORDER BY (id, age)
PRIMARY KEY id
插入数据
insert into t_mt values (1,'张三',18,'2021-06-01','上海'), (2,'李四',19,'2021-02-10','北京'), (3,'王五',12,'2021-06-01','天津'), (1,'马六',10,'2021-06-18','上海'), (5,'田七',22,'2021-02-09','广州');
可以看下索引的地方