为什么会有MongoDB的文章出现,因为最近的一份工作里面用到了MongoDB,这是最直接的原因;其次最近有些许时间,真的是好不容易闲下来;从每天加班到凌晨1点中抽离出来,突然有那么点不适应;由于工作的原因,博客很久没有更新过了,知识的积累速度不免下降了,接下来的时间 慢慢起步吧;有些事情,不是能按照自己的意志来发展的;
什么是MongoDB
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统,旨在为WEB应用提供可扩展的高性能数据存储解决方案。将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。在高负载的情况下添加更多的节点,可以保证服务器性能。
主要特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 支持任何属性的索引
- 数据镜像,使得MongoDB 有更强的扩展性
- 分片技术
- 丰富的表达式,JSON形式标记
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件
- 支持多语言:PHP、C++、JAVA、PYTHON、RUBY
- 文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
安装地址
https://www.mongodb.com/download-center/community
MongoDB 概念解析
SQL术语/概念 | MongoDB术语/概念 | 解释/说明
database | database | 数据库
table | collection | 数据库表/集合
row | document | 数据记录行/文档
column | field | 数据字段/域
index | index | 索引
table joins | | 表连接,MongoDB不支持
primary key | primary key | 主键,MongoDB自动将_id字段设置为主键`database 跟关系型数据库一个概念,collection 集合就是table的概念,document在MongoDB里称之为文档,其实就是一行(row),在mysql里一列叫做column,而MongoDB与之对应的就是field,索引都叫index,主键野叫primary key,MongoDB不需要显示设置,直接把"_id"称之为主键,最后MongoDB不支持表连接(可以使用嵌入文档达到同样的效果);
MongoDB数据类型
- String 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。
- Integer 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。
- Boolean 布尔值。用于存储布尔值(真/假)。
- Double 双精度浮点值。用于存储浮点值。
- Min/Max keys 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
- Array 用于将数组或列表或多个值存储为一个键。
- Timestamp 时间戳。记录文档修改或添加的具体时间。
- Object 用于内嵌文档。
- Null 用于创建空值。
- Symbol 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。
- Date 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。
- Object ID 对象 ID。用于创建文档的 ID。
- Binary Data 二进制数据。用于存储二进制数据。
- Code 代码类型。用于在文档中存储 JavaScript 代码。
- Regular expression 正则表达式类型。用于存储正则表达式。
重要数据类型
- ObjectId类似唯一主键,可以很快的去生成和排序,包含12bytes:其中前4个字节表示创建unix时间戳(UTC时间,格林尼治时间),接着3个字节是机器标识码,紧接着两个字节由进程id组成PID,最后3个字节是随机数;MongoDB中存储的文档必须有一个_id键,默认就是个ObjectId对象,这个对象中有时间戳,可以直接通过getTimeStamp函数获取;
- BSON字符串都是UTF-8编码,
- BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
前32位是一个 time_t 值(与Unix新纪元相差的秒数)
后32位是在某秒中操作的一个递增的序数 - 日期类型标识当前距离Unix新纪元(70年1月1日),负数表示1970年之前的日期
操作一番
下载之后启动MongoDB,进入到MongoDB的shell界面
- show dbs:查看所有数据库
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
- show dbs为什么没看到test库,是因为test库中没有数据。
- db: 查看库中所有的collections(相当于mysql的show tables)
- use local: 指定链接的数据库;如果不存在就会创建数据库(use jack),创建完成之后需要插入一条数据才能用show dbs 看到这个数据库;
- 删除集合:db.jack.drop(); 就像mysql的删除表,返回值成功是bool
- 删除数据库:db.dropDatabase();
文档操作
- 插入文档:db.jack.insert({"name":"jack"}),如果没有创建数据库直接插入,则集合将保存到默认的test库;如果插入的_id 已经存在,“[Error] index 0: 11000 - E11000 duplicate key error collection:“ 将有错误抛出;
- 更新文档:db.lee.update({_id:ObjectId('62aa9b80e9b90dbc49dca3ed')},{$set:{'test':'jack handsome'}},{multi:true}); 第一个花括号中间是条件,第二个是要更新的字段名和值,第三个是只同样条件下更新多条数据;
- 查询文档:db.jack.find(query,projection) query :可选,使用查询操作符指定查询条件;projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略);db.jack.findOne() 返回一条数据;
- 条件操作符
- 等于:db.jack.find({"test":5})
- 小于:db.jack.find({"test":{$lt:5}})
- 小于等于: db.jack.find({"test":{$lte:5}})
- 大于:db.jack.find({"test":{$gt:5}})
- 大于等于:db.jack.find({"test":{$gte:5}})
- 不等于:db.jack.find({"test":{$ne:5}})
- and条件:db.jack.find({"test":5,"other":6})
- or 条件:db.jack.find({$or:[{"test":5},{"other":7}]}) //这里注意有俩大括号 and只有一个
- and 和 or连用:db.jack.find({"ok":1,$or:[{"name":"jack",{"age":18}}]})
这就类似于 mysql的 where ok=1 and (name='jack' or 'age'=18);
- $type 操作符
- $type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
- db.col.find({'title':{$type:2}}) 表示查找的title类型为string类型,2也可以写作'string'
- 类型有多种 Data(9),String(2),Array(4), 括号里的代表对应的数字
- limit() 与Skip() 方法
- limit(1) 读取符合条件之后的第一条
- skip(1) 跳过第一条 读取剩余的
- sort() 排序:sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
索引
索引是特殊的数据结构,它存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
- 条件操作符
- 创建索引
- 创建一个名为title_1的按升序的唯一索引,如果你想按降序来创建索引指定为 -1
- db.col.createIndex({'title':1},{'name:title_1','unique':true})
- 创建联合索引,其中background:true,是因为建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,默认值为false。
- db.col.createIndex({'title':1,'description':1},{'name':'td_1','background':true})
- 查看索引
- db.col.getIndexes() 查看集合索引
- db.col.totalIndexSize() 查看集合索引大小 //57344
- db.col.dropIndexes() 删除集合所有索引 ,主键的索引是没法通过这个方法删掉的
- db.col.dropIndex("索引名称") 删除集合指定索引
聚合
- aggregate:
- sum
- 按照by_user字段分组,并累加行数的值
- db.book.aggregate([{$group:{_id:"$by_user",num_tutorial:{$sum:1}}}])
- 按照by_user字段分组,并累加likes字段的值
- db.book.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
- avg
- db.book.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
- min & max
- db.book.aggregate([{$group:{_id:"$by_user",num:{$min:"$likes"}}}])
- db.book.aggregate([{$group:{_id:"$by_user",num:{$max:"$likes"}}}])
- push
- 将值加入一个数组中,不会判断是否有重复的值。 此例结果中会出现一个url的数组,元素为不同的url字段的值
- db.book.aggregate([{$group:{_id:"$by_user",url:{$push:"$url"}}}])
- addToSet
- 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。
- db.book.aggregate([{$group:{_id:"$by_user",url:{$addToSet:"$url"}}}])
- first
- 根据资源文档的排序获取第一个文档数据。
- db.book.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
- last
- 根据资源文档的排序获取最后一个文档数据
- db.book.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
- sum
管道
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
-
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 (也叫投影,投影意思是只选择必要的数据而不是选择一个文件的数据的整个)
- 场景1只获取部分字段,并把title的字段名重命名为“gg”
- db.book.aggregate({$project:{_id:0,gg :"$title",by_user:1}})
- 场景2 虚假数据,每个点赞数都乘以2
- db.book.aggregate({$project:{_id:1,"qty":{"$multiply":["$likes",2 ]}}})
- 场景3 查询部分字段,by_user 等于李白的文档,by_user 会变成true或者false
- db.book.aggregate({$project:{_id:1,by_user:{"$eq":["$by_user","Neo4j"]}}})
- 场景4 日期查询
- db.book.aggregate({$project:{_id:1,dateInfo:{day:{ $dayOfYear:"$date"},year:{$year:"$date"}}})
- 返回示例:{_id:"x45sdf85s74d",dateInfo:{day:160,year:2022}}
- 场景1只获取部分字段,并把title的字段名重命名为“gg”
-
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- db.book.aggregate([{$match: {likes: {$gt: 70, $lte: 110}}}])
- 表示likes字段的值 大于70或小于等于110
-
$limit:用来限制MongoDB聚合管道返回的文档数。
-
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
-
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
-
$group:将集合中的文档分组,可用于统计结果。
-
$sort:将输入文档排序后输出。
-
$geoNear:输出接近某一地理位置的有序文档。
MongoDB 复制
MongoDB复制是将数据同步在多个服务器的过程。
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
复制还允许您从硬件故障和服务中断中恢复数据
复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
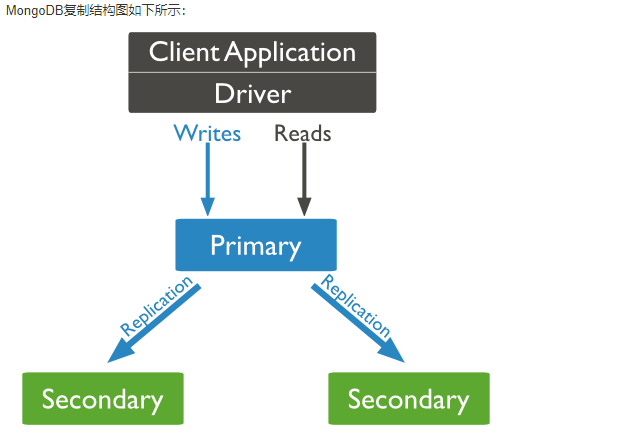
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
MongoDB中你只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster() 。
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
MongoDB 分片
分片
在Mongodb里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求。
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
使用分片的原因
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足。
- 本地磁盘不足
- 垂直扩展价格昂贵
三个主要组件:
Shard:
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组成一个replica set承担,防止主机单点故障
Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
MongoDB监控
MongoDB中提供了mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
mongostat是mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongostat命令,如下所示:
D:\set up\mongodb\bin>mongostat
mongotop 命令
mongotop也是mongodb下的一个内置工具,mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongotop命令,如下所示:
D:\set up\mongodb\bin>mongotop